
Autoria
Fundado em 1985 pelos cineastas japoneses Hayao Miyazaki, Isao Takahata, Toshio Suzuki e Yasuyoshi Tokuma, o Studio Ghibli é um dos estúdios de animação japonesa mais famosos ao redor do mundo.
Além de serem reconhecidos pelos traços e cores muito singulares de seus personagens e cenários, os filmes, curtas e comercias do Studio Ghibli são muito aclamados pela crítica e pelo público devido, principalmente, à sensibilidade dos temas que cerceiam suas histórias e a maneira como elas são contadas para nós.

Por isso tudo, que tal “scrapear” (ou raspar) a página do Studio Ghibli, na Wikipédia a maior enciclopédia colaborativa web do mundo, e coletar os dados de todos os filmes já lançados por esse estúdio de cinema? Scrapers e Ghibli-fãs, uni-vos!
Para quem não conhece os filmes, muitos estão disponíveis na Netflix!
Etapas do scraping
Nesta seção, vamos apresentar cada uma das etapas necessárias para raspar os dados sobre os filmes do Studio Ghibli, no site da Wikipédia. Os processos vão envolver imitar a requisição de busca do navegador e “parsear” os arquivos obtidos, iterando-os com elementos para o tratamento dos erros e de barras de progresso. É importante mencionar, ainda, que a Wikipédia é um site estático escrito em HTML.
Para tanto, vamos utilizar os pacotes R httr para acessar a web; xml2 e rvest para extrair dados de arquivos HTML; purrr para iterar e identificar erros; progressr para incluir barras de progresso; o queridinho tidyverse para a manipulação e visualização dos dados extraídos; e, já que estamos falando de Studio Ghibli, ghibli para colorir nossos gráficos como um filme criado pelo próprio Miyazaki e cia.
Mas não se preocupe porque ao longo da apresentação dos códigos vamos sempre corresponder às funções ao seus respectivos pacotes (por meio do ::) para você saber exatamente com o que está lidando.
Requisição
Inicialmente, inspecionamos a página do Studio Ghibli na Wikipédia para encontrar os elementos em HTML que estão associados exclusivamente às informações dos filmes (como título, ano de lançamento, duração, diretor, elenco etc). Felizmente, esses dados estão todos resumidos em uma única tabela dentre a única tabela que existe na página (na Seção Filmografia, para ser mais exata) - o que deixou a tarefa de raspagem muito mais fácil, por sinal.
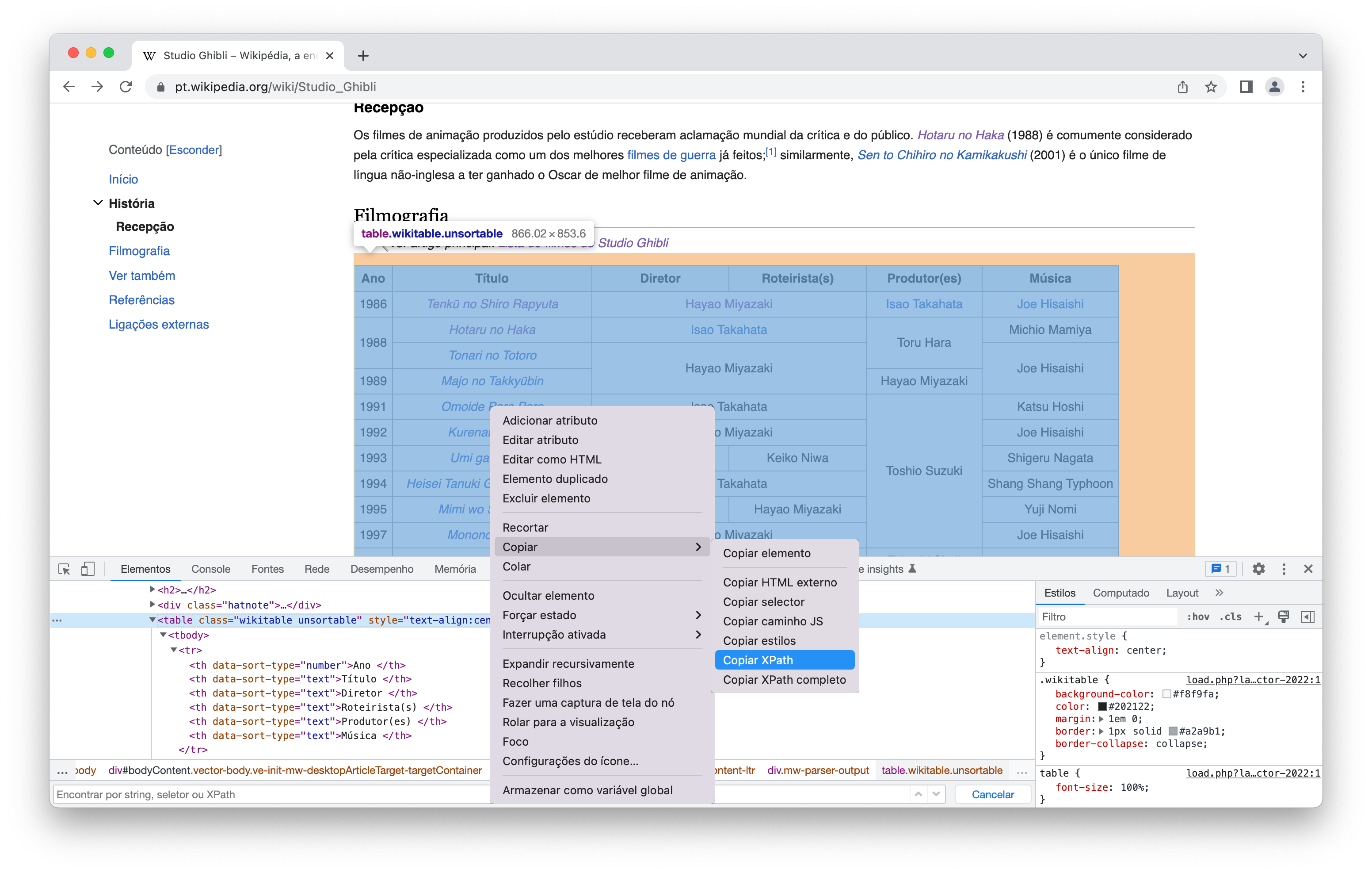
Em primeiro lugar, vamos coletar somente os dados apresentados nessa tabela. Assim, simulamos a requisição apenas com a URL do site, sem deixar de salvar (com o nome filmes_ghibli.html) a página requerida no diretório output/. Como coletar essa tabela se trata de um scraping muito simples, já no próximo passo é possível ler o elemento HTML cujo parâmetro XPath é igual a //*[@id='mw-content-text']/div[1]/table[3], obtido conforme mostra a Figura 2.
O código para o processo da requisição e leitura da tabela em HTML pode ser visto a seguir. Obs.: usamos a função xml_find_first() pois, nesse caso, existia uma única tabela.
# URL da página do Wikipédia
u_ghibli <- "https://pt.wikipedia.org/wiki/Studio_Ghibli"
# requisicao GET
r_ghibli <- httr::GET(
u_ghibli,
httr::write_disk("output/filmes_ghibli.html", overwrite = TRUE) # salvar pagina no disco
)
# coletando a tabela
tabela_ghibli <- r_ghibli |>
xml2::read_html() |> # ler arquivo HTML
xml2::xml_find_first("//*[@id='mw-content-text']/div[1]/table[3]") # parametro XPathA tabela (ainda em HTML, lembrando) que acabamos de obter só contém as informações mais gerais dos filmes do Studio Ghibli. Mas… e se quisermos montar uma base de dados em que seja possível, por exemplo, analisar sobre a duração, gênero e elenco dos filmes? Bem, para esse fim, vamos continuar utilizando a tabela anterior, que, como podemos observar na Figura 2, está sob a tag <table> e o atributo class='wikitable unsortable'. Percebam, ainda, agora na Figura 3, que os títulos são links (identificados com a tag <a>) que direcionam para as páginas individuais de cada um dos filmes, locais onde estão as informações pelas quais estamos interessados.
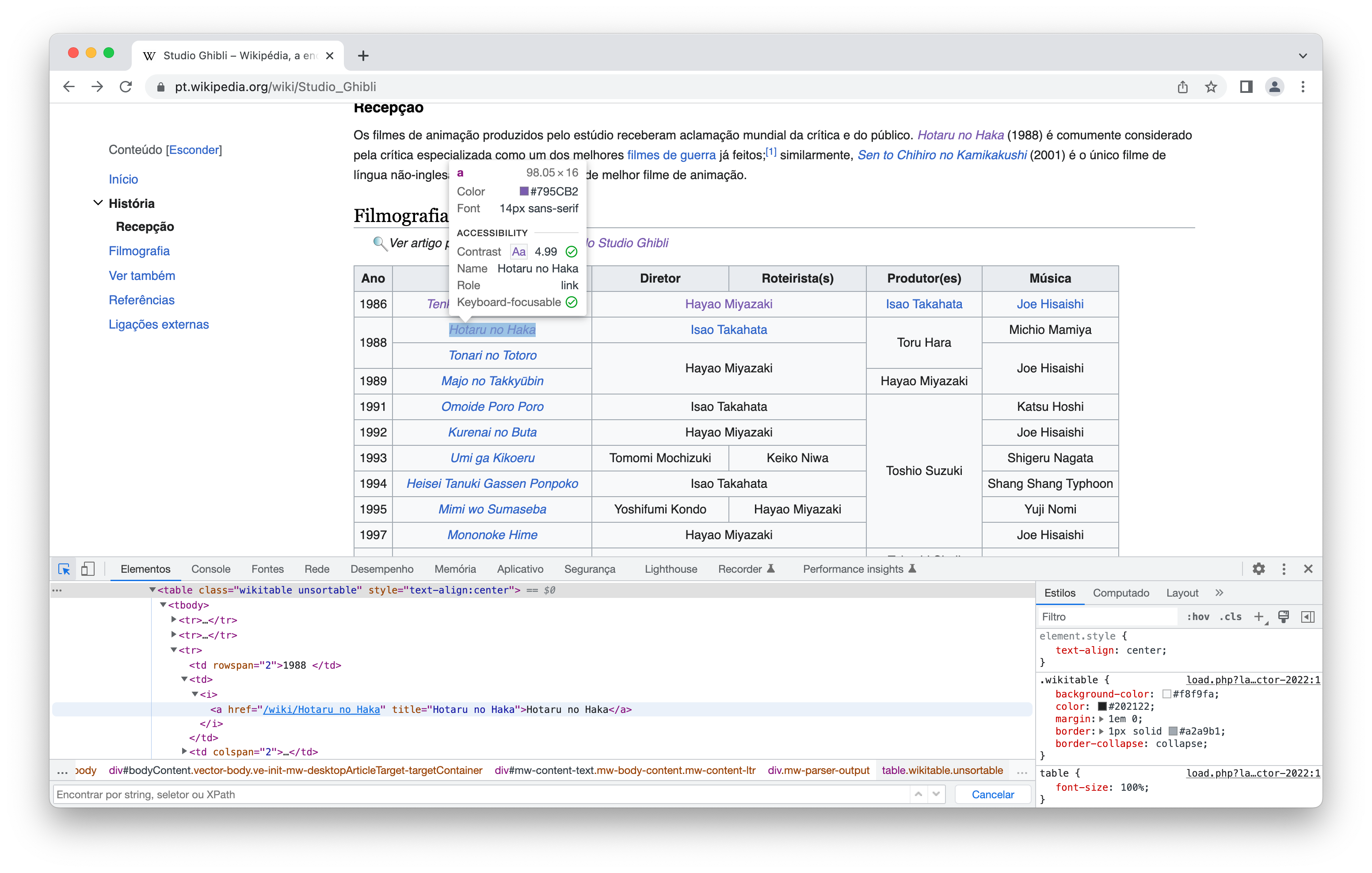
Para extrair esses links, precisamos encontrar todos os links disponíveis na tabela cuja classe é do tipo 'wikitable unsortable'. Logo, lemos a página HTML e coletamos todos os elementos (ou nós) que fazem parte das tags <a> e os atrbiutos do tipo href. Para tal tarefa, construímos o seguinte código:
links_filmes <- r_ghibli |>
xml2::read_html() |> # ler arquivo HTML
xml2::xml_find_all("//table[@class='wikitable unsortable']//a") |> # coletar todos os nos da tabela dentro das tags <a>
xml2::xml_attr("href") # coletar atributos href
links_filmes
#> [1] "/wiki/Tenk%C5%AB_no_Shiro_Rapyuta"
#> [2] "/wiki/Hayao_Miyazaki"
#> [3] "/wiki/Isao_Takahata"
#> [4] "/wiki/Joe_Hisaishi"
#> [5] "/wiki/Hotaru_no_Haka"
#> [6] "/wiki/Isao_Takahata"
#> [7] "/wiki/Tonari_no_Totoro"
#> [8] "/wiki/Majo_no_Takky%C5%ABbin"
#> [9] "/wiki/Omoide_Poro_Poro"
#> [10] "/wiki/Kurenai_no_Buta"
#> [11] "/wiki/Umi_ga_Kikoeru"
#> [12] "/wiki/Heisei_Tanuki_Gassen_Ponpoko"
#> [13] "/wiki/Mimi_wo_Sumaseba"
#> [14] "/wiki/Mononoke_Hime"
#> [15] "/wiki/H%C5%8Dhokekyo_Tonari_no_Yamada-kun"
#> [16] "/wiki/A_Viagem_de_Chihiro"
#> [17] "/wiki/O_Reino_dos_Gatos"
#> [18] "/wiki/Hiroyuki_Morita"
#> [19] "/wiki/Hauru_no_Ugoku_Shiro"
#> [20] "/wiki/Contos_de_Terramar"
#> [21] "/wiki/Goro_Miyazaki"
#> [22] "/wiki/Gake_no_ue_no_Ponyo"
#> [23] "/wiki/Kari-gurashi_no_Arietti"
#> [24] "/wiki/Hiromasa_Yonebayashi"
#> [25] "/wiki/Kokuriko-zaka_Kara"
#> [26] "/wiki/Kaze_Tachinu"
#> [27] "/wiki/O_Conto_da_Princesa_Kaguya"
#> [28] "/wiki/Yoshiaki_Nishimura"
#> [29] "/wiki/Omoide_no_Marnie"
#> [30] "/wiki/%C4%80ya_to_Majo"
#> [31] "/wiki/Kimitachi_wa_Dou_Ikiru_ka"No entanto, os 31 links gerados são da forma /wiki/nome_do_filme, ou seja, inválidos. Validamo-os com o próximo código:
links_filmes <- paste0("https://pt.wikipedia.org", links_filmes)
head(links_filmes)
#> [1] "https://pt.wikipedia.org/wiki/Tenk%C5%AB_no_Shiro_Rapyuta"
#> [2] "https://pt.wikipedia.org/wiki/Hayao_Miyazaki"
#> [3] "https://pt.wikipedia.org/wiki/Isao_Takahata"
#> [4] "https://pt.wikipedia.org/wiki/Joe_Hisaishi"
#> [5] "https://pt.wikipedia.org/wiki/Hotaru_no_Haka"
#> [6] "https://pt.wikipedia.org/wiki/Isao_Takahata"Uma vez corrigidos, podemos fazer a requisição de todas as páginas dos filmes de uma só vez, iterando o processo de tal maneira que algum erro que aconteça em alguma requisição seja identificado.
A primeira função que vamos criar é a get_links(), cujo papel é simplesmente obter uma requisição da mesma forma que havíamos feito inicialmente.
get_links <- function(links, ids) {
arquivo <- paste0("output/", ids, ".html")
r <- httr::GET(links, write_disk(arquivo, overwrite = TRUE))
arquivo
}A segunda função que vamos constuir, a get_progresso(), vai obter as requisições por meio da função get_links() adicionada da informação de erro com o auxílio da função purrr::possibly(). Vejam que, caso aconteça algum problema durante a requisição feita pela get_links(), a seguinte mensagem de erro aparecerá: “ERRO NA REQUISIÇÃO”. A mensagem pode ser escrita de acordo com o gosto do leitor, vale frisar.
Bom, já ao utilizar a função progressr::with_progress(), incluímos uma barra de progresso à iteração. Dois comentários importantes a serem feitos: (1) a função purrr::possibly() permite o andamento da iteração mesmo se houver algum erro no meio do caminho, e se ocorrer algum erro, ela identifica exatamente em qual momento o erro aconteceu; e (2) a barra de progresso serve para o acompanhamento de cada passo da iteração (Figura 4).
# funcao para obter as requisicoes com erro
get_progresso <- function(links, ids, progresso) {
# progresso
progresso()
# mapear erros nas requisicoes
get_erro <- purrr::possibly(get_links, otherwise = "ERRO NA REQUISIÇÃO")
get_erro(links, ids)
}
# obtendo as requisicoes com erro e barra de progresso
progressr::with_progress({
# barra de progresso
progresso <- progressr::progressor(length(links_filmes))
purrr::map2(
links_filmes, seq_along(links_filmes),
get_progresso, p = progresso
)
})
#> [[1]]
#> [1] "output/1.html"
#>
#> [[2]]
#> [1] "output/2.html"
#>
#> [[3]]
#> [1] "output/3.html"
#>
#> [[4]]
#> [1] "output/4.html"
#>
#> [[5]]
#> [1] "output/5.html"
#>
#> [[6]]
#> [1] "output/6.html"
#>
#> [[7]]
#> [1] "output/7.html"
#>
#> [[8]]
#> [1] "output/8.html"
#>
#> [[9]]
#> [1] "output/9.html"
#>
#> [[10]]
#> [1] "output/10.html"
#>
#> [[11]]
#> [1] "output/11.html"
#>
#> [[12]]
#> [1] "output/12.html"
#>
#> [[13]]
#> [1] "output/13.html"
#>
#> [[14]]
#> [1] "output/14.html"
#>
#> [[15]]
#> [1] "output/15.html"
#>
#> [[16]]
#> [1] "output/16.html"
#>
#> [[17]]
#> [1] "output/17.html"
#>
#> [[18]]
#> [1] "output/18.html"
#>
#> [[19]]
#> [1] "output/19.html"
#>
#> [[20]]
#> [1] "output/20.html"
#>
#> [[21]]
#> [1] "output/21.html"
#>
#> [[22]]
#> [1] "output/22.html"
#>
#> [[23]]
#> [1] "output/23.html"
#>
#> [[24]]
#> [1] "output/24.html"
#>
#> [[25]]
#> [1] "output/25.html"
#>
#> [[26]]
#> [1] "output/26.html"
#>
#> [[27]]
#> [1] "output/27.html"
#>
#> [[28]]
#> [1] "output/28.html"
#>
#> [[29]]
#> [1] "output/29.html"
#>
#> [[30]]
#> [1] "output/30.html"
#>
#> [[31]]
#> [1] "output/31.html"Nenhum “ERRO NA REQUISIÇÃO”, yes!
Ah, na Figura 4 é possível ter uma ideia de como é uma barra de progresso.
Parsing
Ao realizar raspagem de dados, a etapa de parsing nada mais é do que processar os dados brutos, que geralmente estão nos formatos .html ou .json, e posteriormente organizá-los de modo que consigamos realizar análises. Em nosso caso, coletamos dados .html tanto no cenário em que queríamos as informações expostas na tabelona da página do Studio Ghibli quanto no cenário em que buscamos as informações dos filmes em cada um dos links direcionáveis dispostos nessa mesma tabela. Em ambas as situações, transformamos os dados para um data frame (ou um tibble) ao fazer uma aplicação simples com a função rvest::html_table().
Notem que, no segundo cenário, optamos pelo arquivo 5.html. Ele se refere ao filme “O Túmulo de Vagalumes”, o filme do Studio Ghibli preferido desta que vos escreve - mas o processo de parsing para qualquer um dos 31 arquivos gerados é o mesmo, caso seu filme favorito seja outro. Nesse caso, quando aplicamos a função mágica rvest::html_table(), o R retorna uma lista com 8 elementos, pois lembre-se que foram coletados todos os nós das tags <a> e todos os atributos da forma href.
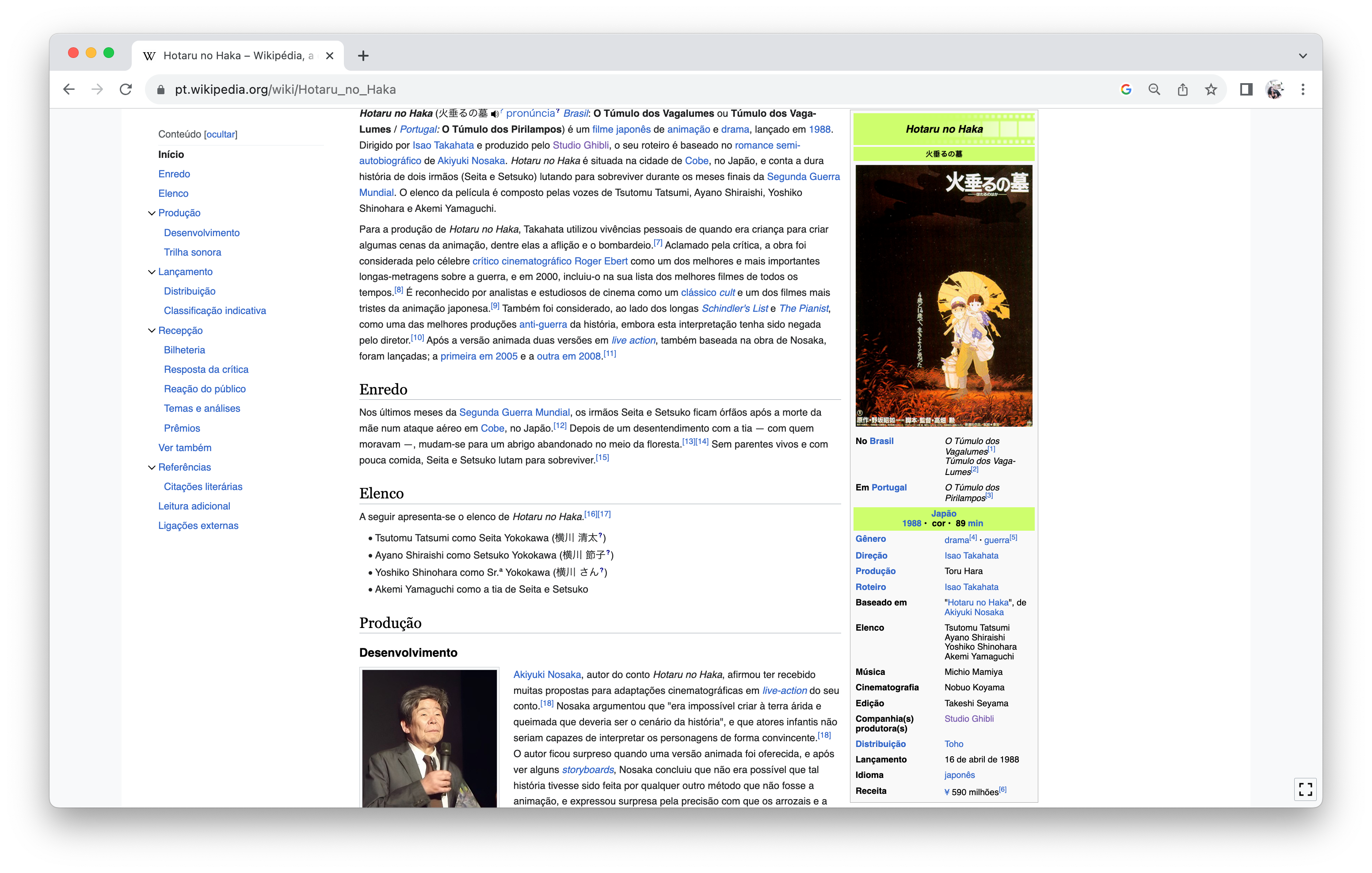
Para esse post, vamos nos limitar ao primeiro elemento ([[1]]), que corresponde ao box à direita na página https://pt.wikipedia.org/wiki/Hotaru_no_Haka (Figura 5), o qual contém informações bastante interessantes para uma análise sucinta do filme.
# primeiro cenario
tabela_ghibli <- tabela_ghibli |>
rvest::html_table(header = TRUE) # transformar dados HTML em tibble
tabela_ghibli
#> # A tibble: 23 × 6
#> Ano Título Diretor `Roteirista(s)` `Produtor(es)` Música
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 1986 Tenkū no Shiro Rapyuta Hayao … Hayao Miyazaki Isao Takahata Joe H…
#> 2 1988 Hotaru no Haka Isao T… Isao Takahata Toru Hara Michi…
#> 3 1988 Tonari no Totoro Hayao … Hayao Miyazaki Toru Hara Joe H…
#> 4 1989 Majo no Takkyūbin Hayao … Hayao Miyazaki Hayao Miyazaki Joe H…
#> 5 1991 Omoide Poro Poro Isao T… Isao Takahata Toshio Suzuki Katsu…
#> 6 1992 Kurenai no Buta Hayao … Hayao Miyazaki Toshio Suzuki Joe H…
#> 7 1993 Umi ga Kikoeru Tomomi… Keiko Niwa Toshio Suzuki Shige…
#> 8 1994 Heisei Tanuki Gassen Pon… Isao T… Isao Takahata Toshio Suzuki Shang…
#> 9 1995 Mimi wo Sumaseba Yoshif… Hayao Miyazaki Toshio Suzuki Yuji …
#> 10 1997 Mononoke Hime Hayao … Hayao Miyazaki Toshio Suzuki Joe H…
#> # ℹ 13 more rows# segundo cenario
tumulo_vagalumes <- xml2::read_html("output/5.html") |>
rvest::html_table() # transformar dados HTML em tibble
tumulo_vagalumes
#> [[1]]
#> # A tibble: 19 × 2
#> `Hotaru no Haka` `Hotaru no Haka`
#> <chr> <chr>
#> 1 .mw-parser-output .noitalic{font-style:normal}火垂るの墓 ".mw-parser-output …
#> 2 Hotaru no Haka "Hotaru no Haka"
#> 3 No Brasil "O Túmulo dos Vagal…
#> 4 Em Portugal "O Túmulo dos Piril…
#> 5 Japão1988 • cor • 89 min "Japão1988 • cor •…
#> 6 Gênero "drama[4]guerra[5]"
#> 7 Direção "Isao Takahata"
#> 8 Produção "Toru Hara"
#> 9 Roteiro "Isao Takahata"
#> 10 Baseado em "\"Hotaru no Haka\"…
#> 11 Elenco "Tsutomu TatsumiAya…
#> 12 Música "Michio Mamiya"
#> 13 Cinematografia "Nobuo Koyama"
#> 14 Edição "Takeshi Seyama"
#> 15 Companhia(s) produtora(s) "Studio Ghibli"
#> 16 Distribuição "Toho"
#> 17 Lançamento "16 de abril de 198…
#> 18 Idioma "japonês"
#> 19 Receita "¥ 590 milhões[6]"
#>
#> [[2]]
#> # A tibble: 20 × 4
#> X1 X2 X3 X4
#> <chr> <chr> <chr> <lgl>
#> 1 N.º "Título" Dura… NA
#> 2 1. "\"Setsuko to Seita ~ Main Title (節子と清太~メ… 2:57 NA
#> 3 2. "\"Yake Nohara (焼野原, Yake Nohara?)\"" 6:51 NA
#> 4 3. "\"Haha no Shi (母の死, Haha no Shi?)\"" 6:34 NA
#> 5 4. "\"Shoka (初夏, Shoka?)\"" 3:14 NA
#> 6 5. "\"Ike no Hotori (池のほとり, Ike no Hotori?)\"" 2:21 NA
#> 7 6. "\"Umi he (海へ, Umi he?)\"" 1:37 NA
#> 8 7. "\"Namiuchigiwa (波打際, Namiuchigiwa?)\"" 1:37 NA
#> 9 8. "\"Higasa (日傘, Higasa?)\"" 2:26 NA
#> 10 9. "\"Sakura no Shita (桜の下, Sakura no Shita?)\"" 1:31 NA
#> 11 10. "\"Dorobbusu (ドロップス, Dorobbusu?)\"" 2:13 NA
#> 12 11. "\"Hikkoshi (引越し, Hikkoshi?)\"" 2:17 NA
#> 13 12. "\"Keimai (兄弟, Keimai?)\"" 2:15 NA
#> 14 13. "\"Hotaru (ほたる, Hotaru?)\"" 4:12 NA
#> 15 14. "\"Hotaru no Haka (ほたるの墓, Hotaru no Haka?)\"" 1:46 NA
#> 16 15. "\"Yuuyake (夕焼け, Yuuyake?)\"" 0:53 NA
#> 17 16. "\"Shura (修羅, Shura?)\"" 3:08 NA
#> 18 17. "\"Hika (悲劇, Hika?)\"" 3:12 NA
#> 19 18. "\"Futari ~ End Title (ふたり~エンドタイトル, Fu… 8:52 NA
#> 20 Duração total: "Duração total:" 58:13 NA
#>
#> [[3]]
#> # A tibble: 3 × 2
#> Classificação Classificação
#> <chr> <chr>
#> 1 Brasil: L[40]/12[34][35]
#> 2 Japão: G[41]
#> 3 Portugal: M/12[37]
#>
#> [[4]]
#> # A tibble: 3 × 6
#> Ano Premiação Categoria `Destinatário(s)` Resultado Ref.
#> <int> <chr> <chr> <chr> <chr> <chr>
#> 1 1988 Blue Ribbon Awards Prêmio E… Isao Takahata Venceu [30]
#> 2 1994 Chicago International Child… Prêmio d… Isao Takahata Venceu [30]
#> 3 1994 Chicago International Child… Prêmio d… Isao Takahata Venceu [30]
#>
#> [[5]]
#> # A tibble: 4 × 2
#> X1 X2
#> <chr> <chr>
#> 1 "Outros projetos Wikimedia também contêm material sobre Hotaru no Haka:" Outr…
#> 2 "" Cita…
#> 3 "" Cate…
#> 4 "" Base…
#>
#> [[6]]
#> # A tibble: 8 × 9
#> `vdeStudio Ghibli` `vdeStudio Ghibli` `vdeStudio Ghibli` `` `` ``
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 "Hayao Miyazaki\nIsao… "Hayao Miyazaki\n… "Hayao Miyazaki\n… <NA> <NA> <NA>
#> 2 "Filmografia" "Longas-metragens… "Longas-metragens" "Ten… Curt… "On …
#> 3 "Longas-metragens" "Tenkū no Shiro R… <NA> <NA> <NA> <NA>
#> 4 "Curtas-metragens" "On Your Mark (19… <NA> <NA> <NA> <NA>
#> 5 "Coproduções" "Shiki-Jitsu (200… <NA> <NA> <NA> <NA>
#> 6 "Jogos eletrônicos" "Jade Cocoon 2 (2… <NA> <NA> <NA> <NA>
#> 7 "Ver também" "Ghibli Museum Li… <NA> <NA> <NA> <NA>
#> 8 ".mw-parser-output .s… ".mw-parser-outpu… ".mw-parser-outpu… <NA> <NA> <NA>
#> # ℹ 3 more variables: `` <chr>, `` <chr>, `` <chr>
#>
#> [[7]]
#> # A tibble: 3 × 2
#> X1 X2
#> <chr> <chr>
#> 1 Longas-metragens "Tenkū no Shiro Rapyuta (1986)\nHotaru no Haka (1988)\nTonar…
#> 2 Curtas-metragens "On Your Mark (1995)\nGiburīzu (2000)\nFirumu Guru Guru (200…
#> 3 Coproduções "Shiki-Jitsu (2000)\nInosensu: Kôkaku kidôtai (2004)\nLa Tor…
#>
#> [[8]]
#> # A tibble: 1 × 2
#> X1 X2
#> <chr> <chr>
#> 1 Controle de autoridade ": Q274520\n WorldCat\nVIAF: 316752206\nANN (animé): 1…Manipulação e visualização dos dados
É verdade que a função rvest::html_table() nos presenteia com dados muito próximos dos desejados, precisando apenas de um ajuste aqui e/ou acolá. Esses “ajustes” são facilmente manipuláveis com as ferramentas da poderosa família tidyverse, como a dplyr, janitor, ggplot2… Porém, como o foco deste post é o web scraping e muito provavelmente você já é um expert em organizar (e apresentar) dados, não entraremos em detalhes em como os códigos desta seção foram construídos. Mas segue a premissa de que primeiro manipulamos os dados, e depois apresentamos os dados.
# manipulacao dos dados
tabela_ghibli <- tabela_ghibli |>
# limpa os nomes das variaveis
janitor::clean_names() |>
# renomeia variaveis
dplyr::rename(roteirista = roteirista_s, produtor = produtor_es) |>
# recodificando variaveis
dplyr::mutate(
roteirista = recode(
roteirista,
`Goro MiyazakiKeiko Niwa` = "Goro Miyazaki, Keiko Niwa",
`Hayao MiyazakiKeiko Niwa` = "Hayao Miyazaki, Keiko Niwa",
`Masashi AndoKeiko NiwaHiromasa Yonebayashi` = "Masashi Ando, Keiko Niwa, Hiromasa Yonebayashi",
`Keiko NiwaEmi Gunji` = "Keiko Niwa, Emi Gunji"
),
produtor = recode(
produtor,
`Takashi ShojiSeiichiro Ujiie` = "Takashi Shoji, Seiichiro Ujiie",
`Toshio SuzukiNozomu Takahashi` = "Toshio Suzuki, Nozomu Takahashi",
`Toshio SuzukiTomohiko Ishii` = "Toshio Suzuki, Tomohiko Ishii",
`Yoshiaki NishimuraSeiichiro Ujiie` = "Yoshiaki Nishimura, Seiichiro Ujiie",
`Hayao MiyazakiToshio Suzuki` = "Hayao Miyazaki, Toshio Suzuki"
)
)
tabela_ghibli
#> # A tibble: 23 × 6
#> ano titulo diretor roteirista produtor musica
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 1986 Tenkū no Shiro Rapyuta Hayao Miyazaki Hayao Miy… Isao Ta… Joe H…
#> 2 1988 Hotaru no Haka Isao Takahata Isao Taka… Toru Ha… Michi…
#> 3 1988 Tonari no Totoro Hayao Miyazaki Hayao Miy… Toru Ha… Joe H…
#> 4 1989 Majo no Takkyūbin Hayao Miyazaki Hayao Miy… Hayao M… Joe H…
#> 5 1991 Omoide Poro Poro Isao Takahata Isao Taka… Toshio … Katsu…
#> 6 1992 Kurenai no Buta Hayao Miyazaki Hayao Miy… Toshio … Joe H…
#> 7 1993 Umi ga Kikoeru Tomomi Mochizu… Keiko Niwa Toshio … Shige…
#> 8 1994 Heisei Tanuki Gassen Ponpoko Isao Takahata Isao Taka… Toshio … Shang…
#> 9 1995 Mimi wo Sumaseba Yoshifumi Kondo Hayao Miy… Toshio … Yuji …
#> 10 1997 Mononoke Hime Hayao Miyazaki Hayao Miy… Toshio … Joe H…
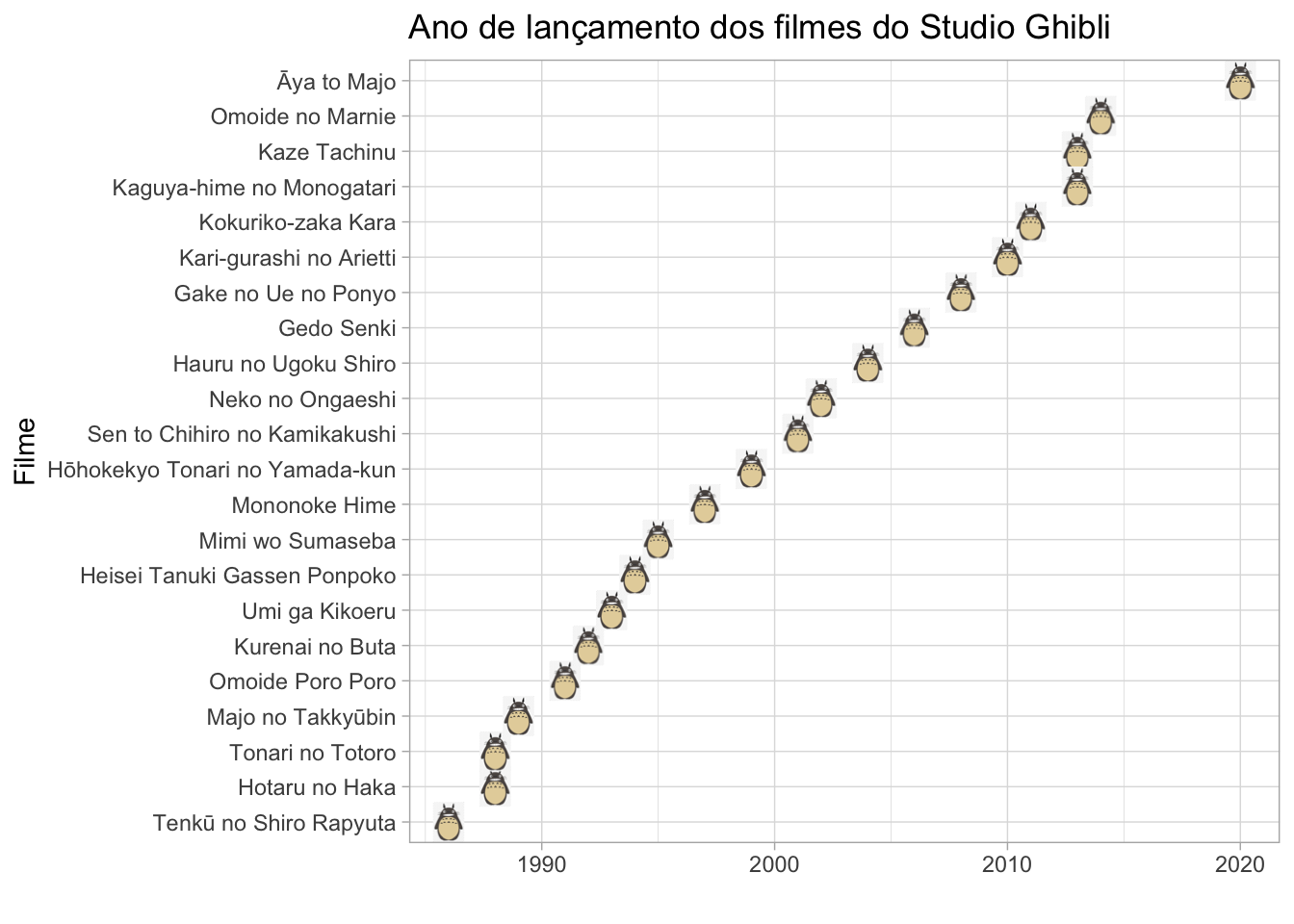
#> # ℹ 13 more rowsNa primeira aplicação, construímos um gráfico para visualizar de forma mais “fofinha” o ano de lançamento dos filmes do estúdio - e nada mais fofinho do que um gráfico cheio de Totorinhos, não é mesmo?
# grafico animado
ghibli <- "ghibli.png" # carrega imagem
tabela_ghibli |>
dplyr::filter(ano != "ASA") |>
# reordena os filmes por ano de lancamento
dplyr::mutate(
ano = as.numeric(ano),
titulo = forcats::fct_reorder(titulo, ano)
) |>
ggplot2::ggplot(aes(x = ano, y = titulo)) +
# adiciona imagem do totoro
ggimage::geom_image(image = ghibli, size = .04) +
# adiciona temas ao grafico
ggplot2::theme_classic() +
ggplot2::theme_light() +
# adicona rotulos ao grafico
ggplot2::labs(
title = "Ano de lançamento dos filmes do Studio Ghibli",
x = "", y = "Filme"
)
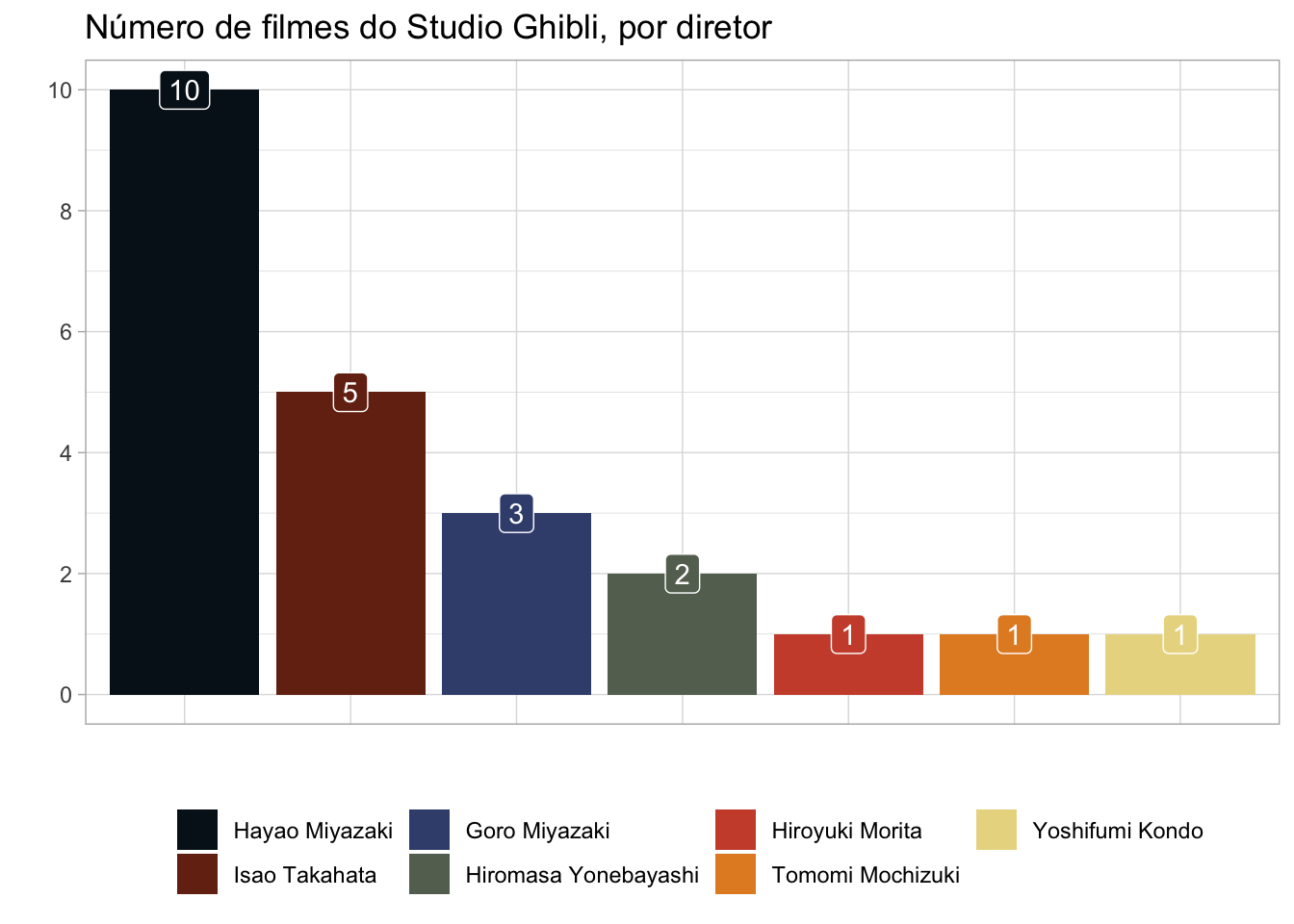
Além de mostrarmos de maneira mais elegante o número de filmes dirigidos pelos seus cineastas. A propósito, oportunidade única para utilizar o pacote ghibli, que contém paletas de cores de vários filmes do Studio Ghibli, como “A Princesa Mononoke” (a escolhida), “Ponyo - Uma Amizade que Veio do Mar” e “A Viagem de Chihiro”.
# grafico de barras
tabela_ghibli |>
# agrupa filmes por diretor
dplyr::group_by(diretor) |>
# conta a quantidade de filmes que cada diretor lancou
dplyr::summarise(n = n()) |>
# reordena em ordem decrescente os diretores por quantidade de filme
dplyr::mutate(diretor = forcats::fct_reorder(diretor, -n)) |>
ggplot2::ggplot(aes(x = diretor, y = n, fill = diretor)) +
ggplot2::geom_bar(stat = "identity") +
ggplot2::scale_y_continuous(breaks = seq(0, 10, by = 2)) +
# adiciona temas ao grafico
ggplot2::theme_classic() +
ggplot2::theme_light() +
# paleta de cores do filme 'princesa mononoke'
ghibli::scale_fill_ghibli_d("MononokeMedium") +
# adiciona rotulos nas barras do grafico
ggplot2::geom_label(
aes(label = n), position = position_dodge(width = 1),
show.legend = FALSE, color = "white"
) +
# adiciona rotulo aos graficos
ggplot2::labs(
title = "Número de filmes do Studio Ghibli, por diretor",
x = "", y = "", color = "diretor"
) +
ggplot2::theme(
legend.title = element_blank(), # remove titulo da legenda
legend.position = "bottom", # posiciona legenda embaixo do grafico
axis.text.x = element_blank(), # remove valores do eixo x
axis.ticks.x = element_blank() # remove ticks do eixo x
)
Por último, como resultado da segunda aplicação, vamos construir uma tabela, uma espécia de ficha técnica, com as informações que foram coletadas do filme “O Túmulo de Vagalumes”. Obs.: optamos por uma análise simples nesse caso. Uma sugestão seria concatenar os dados dos boxs de todos os filmes em uma única base e calcular a média de duração dos filmes ou verificar qual o gênero mais comum entre eles, por exemplo.
# manipulando os dados
tumulo_vagalumes <- tumulo_vagalumes |>
# seleciona o primeiro elemento da lista
purrr::pluck(1) %>%
# remove linhas 1 e 2
.[c(-1, -2), ]
colnames(tumulo_vagalumes) <- c("categoria", "descricao") # renomeia os nomes das variaveis
tumulo_vagalumes <- tumulo_vagalumes |>
# transforma base em formato wide (o que e linha vira coluna)
tidyr::pivot_wider(names_from = "categoria", values_from = "descricao") |>
# organiza os nomes das variaveis
janitor::clean_names() |>
# renomeia variaveis
dplyr::rename(
titulo_br = no_brasil,
titulo_pt = em_portugal,
duracao_min = japao1988_cor_89_min,
produtora = companhia_s_produtora_s,
receita_milhoes = receita
) |>
# organiza variaveis
dplyr::mutate(
titulo_br = stringr::str_sub(titulo_br, end = 22),
titulo_pt = stringr::str_sub(titulo_pt, end = 23),
duracao_min = stringr::str_sub(duracao_min, start = 21, end = 22),
elenco = recode(elenco, `Tsutomu TatsumiAyano ShiraishiYoshiko ShinoharaAkemi Yamaguchi` = "Tsutomu Tatsumi, Ayano Shiraishi, Yoshiko Shinohara, Akemi Yamaguchi"),
genero = recode(genero, `drama[4]guerra[5]` = "drama, guerra"),
lancamento = stringr::str_sub(lancamento, start = 22, end = 31),
receita_milhoes = stringr::str_sub(receita_milhoes, start = 2, end = 5)
)
tumulo_vagalumes
#> # A tibble: 1 × 17
#> titulo_br titulo_pt duracao_min genero direcao producao roteiro baseado_em
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 O Túmulo dos… O Túmulo… 89 drama… Isao T… Toru Ha… Isao T… "\"Hotaru…
#> # ℹ 9 more variables: elenco <chr>, musica <chr>, cinematografia <chr>,
#> # edicao <chr>, produtora <chr>, distribuicao <chr>, lancamento <chr>,
#> # idioma <chr>, receita_milhoes <chr>A tabela:
# tabela
tumulo_vagalumes |>
# retorna base em formato longo (o que e coluna vira linha)
tidyr::pivot_longer(
cols = 1:17,
names_to = "categoria", values_to = "descricao"
) |>
# cria tabela
gt::gt() |>
gt::tab_header(
title = "Túmulo de Vagalumes",
subtitle = "Ficha do filme"
)| Túmulo de Vagalumes | |
|---|---|
| Ficha do filme | |
| categoria | descricao |
| titulo_br | O Túmulo dos Vagalumes |
| titulo_pt | O Túmulo dos Pirilampos |
| duracao_min | 89 |
| genero | drama, guerra |
| direcao | Isao Takahata |
| producao | Toru Hara |
| roteiro | Isao Takahata |
| baseado_em | "Hotaru no Haka", de Akiyuki Nosaka |
| elenco | Tsutomu Tatsumi, Ayano Shiraishi, Yoshiko Shinohara, Akemi Yamaguchi |
| musica | Michio Mamiya |
| cinematografia | Nobuo Koyama |
| edicao | Takeshi Seyama |
| produtora | Studio Ghibli |
| distribuicao | Toho |
| lancamento | 1988-04-16 |
| idioma | japonês |
| receita_milhoes | 590 |
Legal, né?
Para finalizar, deixo uma das definições de amor mais legais que já ouvi, que não poderia ter vindo se não pela mente brilhante de Hayao Miyazaki:
“Tornei-me cético em relação à regra não escrita de que só porque um menino e uma menina aparecem no mesmo filme, um romance deve acontecer. Em vez disso, quero retratar um relacionamento um pouco diferente, onde os dois se inspiram mutuamente para viver – se eu puder, então talvez eu esteja mais perto de retratar uma verdadeira expressão de amor.”
Hasta!